在這個充滿精彩創新的時代,AI徹底改變了日常生活型態,同時ChatGPT等工具透過直觀易操作的文字和語音互動,重新定義生產力標準。隨著採用AI技術的系統持續進步,傳統商業模式、信念與假設均面臨前所未有的挑戰。
語音在新興AI生態系統中扮演什麼角色?身為企業領導者,是否該重新思考經營信念?高品質音訊輸入是否會因為生成式AI興起,重要性日漸降低,或反之成為協助普及AI服務和個人助理的關鍵要素?
AI從得力助手到最佳夥伴
根據問題的內容與形式來調整回答方式,是人類的自然本能。人聲中其實包含了各種提示,可用於判斷發問者的年齡、性別、社會文化背景以及情緒狀態。此外,辨識發問者所處的環境,例如是在機場、辦公室或交通運輸工具上,或是否在從事跑步等體能活動,也有助於判斷發問者的意圖,並據此調整答案或對話模式。
雖然AI的能力已有長足進步,但仍有一種觀點認為,AI輔助功能無法正確預測人類問題的目的,或精準解讀特定訊息。為了改善人機互動,AI在選擇回應措辭時應考慮三個關鍵因素:對聽者的瞭解、聽者的情緒狀態以及環境背景。
在多數情況下,憑藉接收到的音訊訊號,便足以擷取出有用資訊,並以此做出適當回應。與素未謀面的人進行電話或語音會議即是一例。更須考量的是,在無法進行面對面互動的情況下,經過反覆對話後,人們對彼此的觀感會如何變化。
近期研究顯示,即使僅是微調AI的語言回應風格,也會明顯影響人們對其社交能力和個性的看法。因此可合理假設,只要能取得充分且理想的語音輸入內容,未來AI系統將能有效發揮陪伴功能,充當類似人類朋友的角色,例如主動詢問並提供切實回應,或在適當時機單純聆聽而不做出評判。
人類如何接收音訊訊號?
如同口頭溝通,語音訊息也是採用語言和文字來傳達思想、感受和想法。此外,溝通過程中的其他元素,例如音調、速度、音量和背景噪音,都會影響聽者對訊息的整體感知。

圖1 人類聽力臨界值
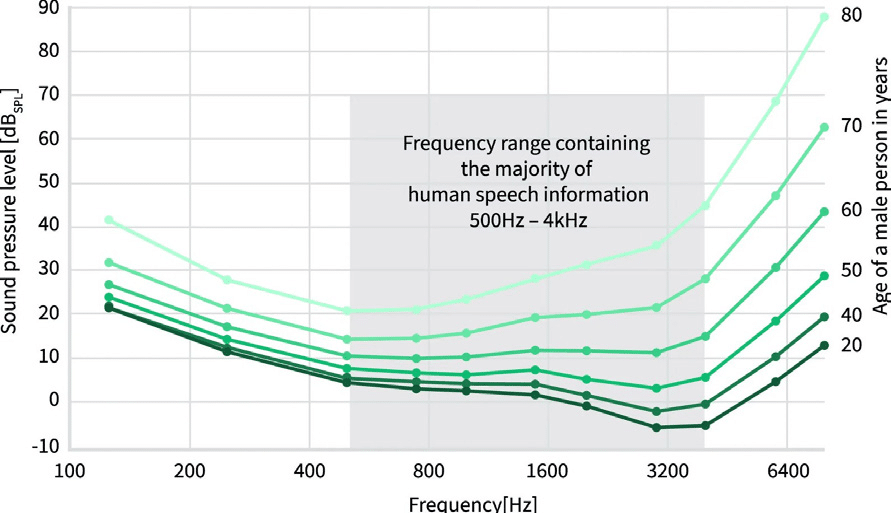
圖2 人類聽力臨界值與年齡的關係
從科學角度來看,頻率和聲壓位準是人耳能感知到音訊訊號的兩大關鍵因素。聲壓位準(SPL)以分貝(dBSPL)為單位,表示周圍環境大氣壓力振盪的聲壓振幅。若SPL為100dBSPL,則相當於割草機或直升機所發出的巨大噪音。
S P L範圍內的最低點(0d B)相當於20μPa聲壓振盪,即具有最佳聽力的健康年輕人在1kHz頻率下的聽力臨界值。所有和語音相關的人類聲音,都屬於100Hz至8kHz的頻段。根據ISO226:2023標準,相應的人類聽力臨界值如圖1所示。
如圖1所示,人耳對500Hz~6kHz範圍內的頻率尤其敏感。在這段頻率中,任何頻率平衡問題都會大幅影響人耳所聽到的語音和樂器音質。在500Hz~4kHz的頻率內,包含了人類語音中會影響語音清晰度的大部分資訊。
其中2kHz左右的頻率尤為重要。5kHz~10kHz的頻率則是音樂悅耳與否的關鍵。這段頻率能讓聲音更顯生動清亮,然而其中所包含的語音資訊相對較少,僅包括ship、chip、zip等字詞開頭的齒音。若降低到6~8kHz左右,則會有損語音清晰度。
眾所皆知,人類的聽力臨界值會隨年齡成長而降低,如圖2所示。
圖2 顯示在聆聽單聲道耳機的條件下,不同年齡段之身體機能正常的男性,其聽力臨界值的衰退情況。在針對女性所做的類似調查中,則顯示女性聽力隨年齡成長而衰退的程度略為較低(ISO 7029:2017)。
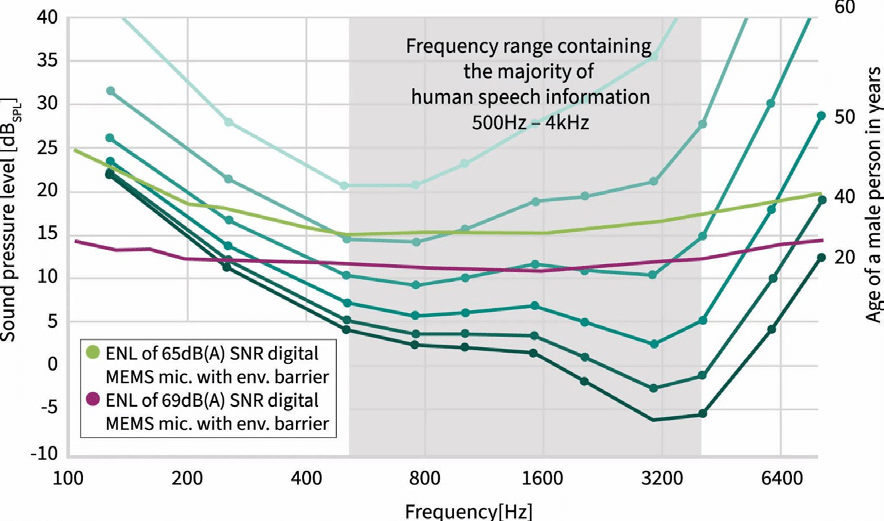
圖3 兩種MEMS麥克風ENL曲線與人類聽力臨界值比較
值得注意的是,即便是好發於40~50歲族群的輕度聽損狀況,也會對個人生活造成重大影響。例如,患有輕度聽損的人在吵雜環境中,可能較難跟上團體對話。此外,也可能會錯過重要的聽覺提示,例如警告訊號或警報。
AI世代的音訊硬體需求
對人類如何感知音訊訊號有更深入瞭解後,回到最初的問題,即目前與未來的AI需要何種程度的音訊輸入品質,才能達到與人類無異的水準。目前市面上大多數消費性裝置都是以MEMS麥克風來錄取音訊訊號。至於逐漸普及於市場的AI個人助理,也是以MEMS麥克風為主流音訊擷取技術。
MEMS麥克風的錄音品質取決於其動態範圍。動態範圍的上限定義為聲學過載點(AOP),會影響麥克風在高SPL下的失真性能。麥克風自有噪音會限制在低階頻譜的動態範圍,麥克風自有噪音的傳統測量標準為訊噪比(SNR),也就是麥克風自有噪音與目標訊號的比例。然而在AI案例中,SNR數值可能不完全可靠,因為SNR在計算上採用AI加權,而此加權方式乃是根據人類感知音訊訊號的狀況。
若錄製訊號的預期接收者是AI,則撇除錄音中人類感知要素的等效雜訊位準(ENL),將是更適合衡量效能的相關麥克風參數。ENL是指在沒有外部聲源的狀況下,麥克風自身產生的訊號,代表能夠產生與麥克風自有噪音相同電壓的聲壓位準。
麥克風跨頻率的ENL基本上可視為麥克風的聽力臨界值。然而這是一項高度簡化的假設,因為音訊鏈中通常還有許多其他元件,包括聲道、額外防水保護以及音訊處理鏈。
圖3為兩種MEMS麥克風ENL曲線與人類聽力臨界值的比較。其中中階和高階MEMS麥克風的1/3倍頻程自有噪音(ENL),比較典型男性的聽力臨界值。圖中綠色實線為65dB(A)SNR麥克風的ENL曲線,且此麥克風內建防塵環境屏障。該對應MEMS麥克風目前已用於多家廠商的高階智慧型手機。
下方紫色線則是廠商如英飛凌最新高階數位麥克風的ENL曲線,該麥克風具有創新環境屏障,可防止微粒和濕氣,2024年才首度搭載於一款高階平板電腦。預計至當年底,高階智慧型手機便會採用效能相當的麥克風。麥克風自有噪音能降低5到10dBSPL可謂一項重大進步,尤其考慮到聲壓是以對數尺度來表示。
雖然英飛凌在降低高階MEMS麥克風的自有噪音方面有進步,但麥克風分辨低聲壓位準的能力仍遠落後於人耳。尤其是2kHz的頻率範圍,對於確保人類聽者能獲得清晰高音質至關重要。年輕人的聽力,與英飛凌最先進的麥克風之間,仍有超過12dBSPL的差異。與目前高階手機所使用的麥克風相比,差距更是達到17dBSPL。此外必須再次強調,此評估僅考慮MEMS麥克風的自有噪音,並未考量到音訊鏈中其他會進一步降低整體效能的雜訊來源。
目前MEMS麥克風的技術侷限,在包含大部分人類語音資訊的頻率範圍(500~4kHz)內最為明顯。即使是市面上最精密的MEMS麥克風,語音理解能力也只能達到60歲老人的水準。根據現有資料,可想見使用最新MEMS麥克風技術的AI虛擬助理,將出現類似老年人的聽力障礙,尤其是在必須於吵雜環境或遠距離追蹤對話的情況下。
AI推升高SNR MEMS麥克風需求
隨著AI飛速發展,高SNR MEMS麥克風的需求不僅不會減慢,反而將加速興起。雖然最新MEMS麥克風仍無法媲美人耳的音訊品質,但已可有效降低自有噪音,對於現有及未來AI裝置將大有助益。進一步改善音訊鏈,例如周圍環境分辨、情境理解、情緒感知、說話者識別和多人對話記錄,將是強化AI功能的關鍵。有了更好的音訊輸入,AI與人類的互動方式將能媲美真人,甚至超乎期待。
此外,改善人機互動將有助於推動全新AI使用案例和服務。例如,假設未來全新版本的Microsoft Copilot不但能總結Teams會議內容,還可以就對話氣氛進行整體評估。
未來AI或許能夠僅憑人類的語音和音訊,重點標示討論的行動項目,或針對重要性進行排序。此外,也有機會增加AI輔助功能,為使用者提供實用建議,協助其瞭解該如何將對話引導至理想方向。
想像一個未來,其中AI能夠進行新求職者的第一輪面試,或僅根據音訊即辨識出說話者,且能達到線上購物所要求的安全水準。以上一切都只是未來AI所能做到的一小部分,未來AI的聽力也許將不亞於甚至超越人類。